





Table of contents
- What is Concurrency? And what is Parallelism?
- What is concurrency needed for?
- Ok, how is concurrency handled in JavaScript?
- Where does the event loop come from?
- What is the general pattern for the Event Loop?
- How is the event loop implemented in browsers?
- How is the event loop implemented in Node.js?
- What are the general principles of multithreading? Something JS specific?
- How does JavaScript work with threads in browser?
- How does JavaScript work with threads in Node.js?
- Conclusion
- References
For quite some time now, JavaScript (JS) has been the language that brings the Web to life. So it's no surprise that since 2014, of all programming and scripting languages, JavaScript has consistently been the most popular technology among software developers, according to Stack Overflow surveys.
As with other programming languages, JavaScript's capabilities are significantly influenced by the runtime environment in which it runs.
One crucial aspect that depends on runtimes, which is the main topic of this discussion, is the Concurrency Model.
In terms of runtimes, Node.js gets the most focus in this discussion, but browsers like Edge, Firefox and others also get decent coverage.
As for reader's prerequisites general knowledge of programming languages, curiosity and critical thinking are the three most important things to have, as here, besides coding, are also explained and illustrated principles, concepts and designs for achieving concurrency. But those who have a basic knowledge of JS and C/C++ could get a fine-grained analysis of the implementations.
For all the readers for whom concepts like timers, promises, threads, event loop, asynchronous behavior and others are just an important piece of magic that JS provides, then this post can help you better understand the depths on which different types of concurrency are achieved in JS runtimes. For those who are veterans of these things, you'll enjoy a good old refresher of the concepts . . . or you might just remember the struggles you overcame learning JavaScript 😂 but either way it's still a post worth reading.
One more thing before we start, doing all this technical "detective" work to understand JS concurrency, depending on the person it might take some time and effort to ponder and understand, so feel free to break it up into several lectures and read it in your own pace, the table of contents should help you with that. Also don't hesitate to bring imagination and a cheerful spirit while reading this, it will always make things more memorable. I am no comedian, but I'll try to plant some fun here and there along the way, after all . . . why so serious?
Alright, enough rhetoric, let's get down to business!
What is Concurrency? And what is Parallelism?
Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.
Well, if you are in a hurry you could just resume to the above quote and move further to the next chapter. But if you want to get a little deeper in these concepts keep reading, it rocks 🚀
First let's clarify a few terminology used here in the context of computer science talk:
- By execution I refer to the process of actualizing instructions scheduled on a central processing unit (CPU)
- A program is a set of instructions and associated data that is kept on computer storage and that can be loaded and executed/run by an operating system.
- A process represents the actual execution of a program containing whatever resources it requires, like CPU, memory and so on.
- By system, in the context of concurrent/parallel system, I refer either to goal-oriented groups of programs, individual programs, or specific areas of a program.
Now, generally speaking, a system that is composed from several parts, is said to be concurrent if: it is able to register progress without needing all its parts to have executed, the order of execution for its constituents could differ and its final result is not influenced by this order. Like, for example, an operating system 🐧 is a pretty common concurrent system.
A parallel system is just a concurrent system that takes a step forward by having and conditionally enforcing the ability of execution at the same time of multiple of its constituents. Also, most of the times, an operating system would be a good example here, given that it's running on a multi-core machine.
Ok, now narrowing it down to the program scope, I would add a few more words about the types of program execution:
- Synchronous execution refers to the execution of a piece of code line by line in a blocking way, that meaning it does not allow the program to deviate from the order of instructions from the piece of code that it is currently running. Think it like a piece of code with a single execution vector/direction that instructions can be ran. This code actually may be even the entire program.
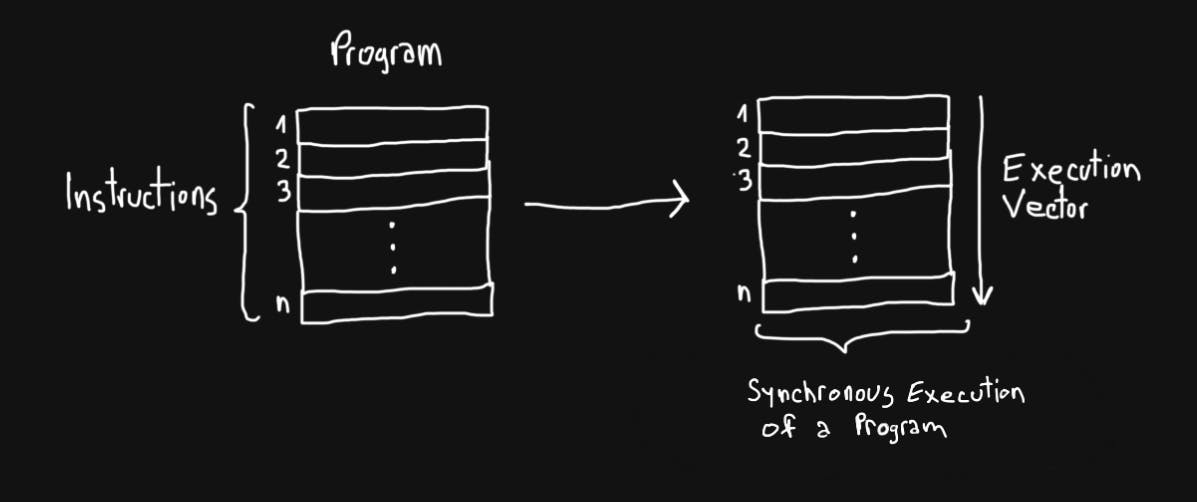
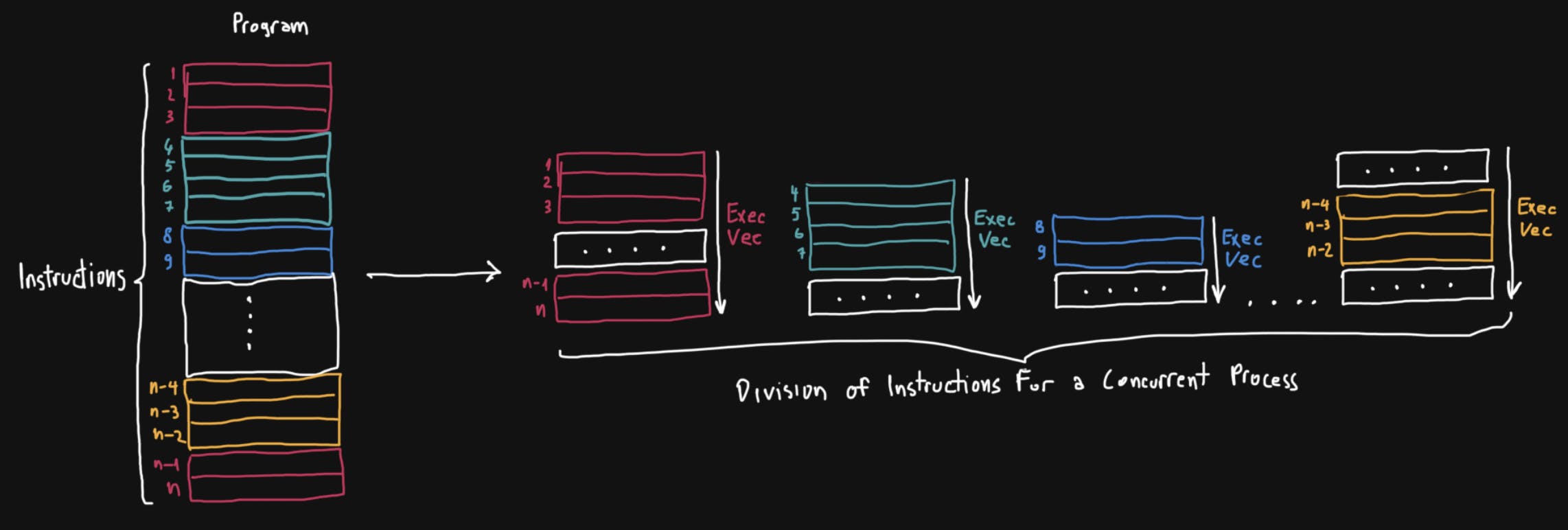
- Asynchronous execution refers to execution of a piece of code that it is not blocking. This usually manifest while invoking subroutines, these are then scheduled to run on the same processing resource after a certain condition is met or they could run on a separate processing resource, in parallel, if the machine allows it. As you might already figured it out, for code to execute this way the program needs to be concurrent.
What is concurrency needed for?
There are many situations in which some systems need concurrency of some sort for, at least, the appearance of simultaneous execution, in order to preserve a minimum line of acceptance between its users. For example, a user wants to be able to navigate through the web page without feeling lag, that being regardless of what different events it triggers, like opening popup windows, loading images, etc.
These situations, on the other hand, are likely to be way more prone to lag if they were to happen on synchronous execution. In this case the processing power of the machine it's a much more important factor in determining fluidity of the user experience. For example fetching images may not always resolve fast enough, even if it takes a few seconds this time would be enough to reduce user acceptance.
Also besides the lag sensation, concurrency, usually parallelism, could be used to increase efficiency and effectiveness of heavy processing programs on multi-core clusters of machines. For example training deep learning models 🤖 could take advantage of a distributed machine cluster.
Ok, how is concurrency handled in JavaScript?
Popular JS runtime environments (such as Chrome, Edge, Firefox, Safari, Node.js, Deno, etc.) approach concurrency by first implementing the event loop (EL) concept, than complementing it with a threading technique and lastly using inter-process communication (IPC). That's it 🎉

In the following chapters we will focus mainly on the first two concepts.
Where does the event loop come from?
Ok, let's explain this a little. The first reminiscences of the event loop in JS runtime environments date way back to 1995, very long ago when dinosaurs were still a thing and the dot-com bubble had yet to happen. But anyways, it appeared in the private browser Netscape Navigator. About this you can find a discussion by Douglas Crockford on the emergence of the event loop concept in the browser.
It is important to keep in mind that event loops adhere to a cooperative mode of multitasking, meaning that one piece of code can hand over the baton to another piece of code only intentionally, there is no mediator such as an operating system scheduling agent to manage access to processing resources for each piece of code.
What is the general pattern for the Event Loop?
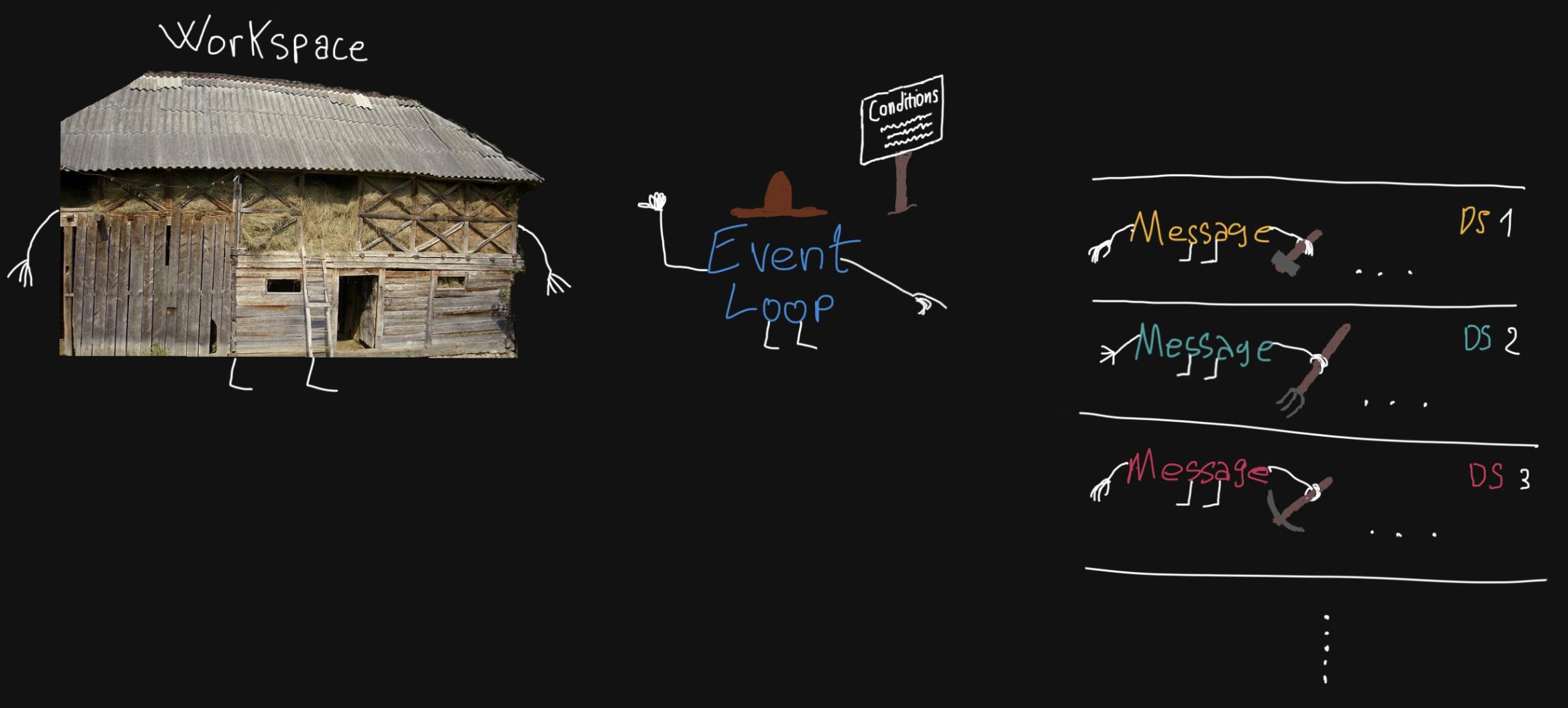
The event loop is a design pattern that is responsible for delegating messages/events from multiple data structures that can be of different types from each other, in a work environment where they can be consumed.
The EL can be conditioned in order to harden priorities for: starting the loop, pausing the loop, choosing messages or stopping the loop. Until it encounters stop signals or is not forcibly stopped, the event loop in principle will loop forever.
How is the event loop implemented in browsers?

Well there is something called The HTML Standard 📄 this dictates the basic specifications that should be followed in the development of browsers. The execution specifications for the event loop are also mentioned there, these specifications differ depending on the type of event loop: window event loop (that is the main event loop), worker event loop, worklet event loop. But it is also worth mentioning that not all browsers respect these specifications the same.
The EL runs on the same thread as the messages it manages. Depending on the browser, the event loop implementation can be done in a separate library, for example browsers like Chrome and Edge that are based on Google's Chromium project use the event loop implementation of the libevent library, on the other hand Firefox seems to use an in-house implementation, that is quite elusive to find but some point of reference it would be found in the searchfox repo. Broadly speaking, event loop implementations are a conditional while loop.
Types of operations
When it comes EL operations, there are two main types of them in browsers:
- Task
- Microtask
Besides these two, you could also add the requestAnimationFrame (rAF) operation for the Window EL, this operation represents the code that is executed before rendering the next frame on the screen. For this reason, it is recommended that in rAF, the code should be related to the visual effects to be rendered. You can watch nice visuals of it and the event loop in Jake Archibald talk at JSConf.
There are no subtypes of tasks and microtasks. The prioritization for both types in there respective categories is done depending on the moment in which the operation was invoked.
The order of operations
As discussed above, broadly speaking, browser operations can be divided into tasks and microtasks.
The order of operations being:
- A Task
- All Microtasks (including those newly added by the currently running Microtasks, this may clog the EL)
- Pre-rendering (All Animation Callbacks from rAFs, except those added by the rAFs themself)
- Rendering (recognition of the CSS, then the layout by the browser followed by the actual printing of the page).
The Pre-rendering and rendering parts could actually be skipped if the browsers decides so, often from optimization issues. Also in the case of Worker and Worklet, this operations do not refer to directly accessing the Document Object Model (DOM) and its related objects, this not even being allowed, but rather to a virtual canvas specific to each Worker or Worklet.
Depending on the browser and version, the order of operations may differ more or less from the HTML Standard. But, in general, browsers based on Chromium respect this standard more.
Examples of event loop operations in browser
The simple script below should have similar results regardless of which type of EL it runs on:
function workTime(mls) {
const startDate = performance.now();
let currentDate = null;
do {
currentDate = performance.now();
} while (currentDate - startDate < mls);
}
function runMicrotask() {
console.log("Start Microtask");
workTime(1000);
eventLoopPhasesArray[index++] = "Microtask";
console.log("Microtask completed");
}
function runTask() {
console.log("Start Task");
workTime(1000);
eventLoopPhasesArray[index++] = "Task";
console.log("Task completed");
console.log(eventLoopPhasesArray);
}
function runAnimationCallback() {
eventLoopPhasesArray[index++] = "Animation callback";
console.log("Animation callback completed");
requestAnimationFrame(runAnimationCallback);
}
const eventLoopPhasesArray = [];
let index = 0;
eventLoopPhasesArray[index++] = "Start main script";
console.log("Start script task");
setTimeout(runTask, 0);
queueMicrotask(runMicrotask);
workTime(1000);
eventLoopPhasesArray[index++] = "End main script";
console.log("Script task completed");
requestAnimationFrame(runAnimationCallback);
A few observations in here:
- Be careful how you try to deduce the order of operations. For example, if you rely on console.log, you should know that it does not have a standardized implementation and may produce inconsistent results depending on the browser and version.
- Below, the order of operations will be judged using array representation, a web API agnostic method. Each operation has its own string or several characteristic strings that it pushes into an array. Depending on the order of these strings in the array, the order of operations is established. Console.log is still used to exemplify possible misleading due to its non-standardized implementation or potential bugs in the browser.
Firefox results:
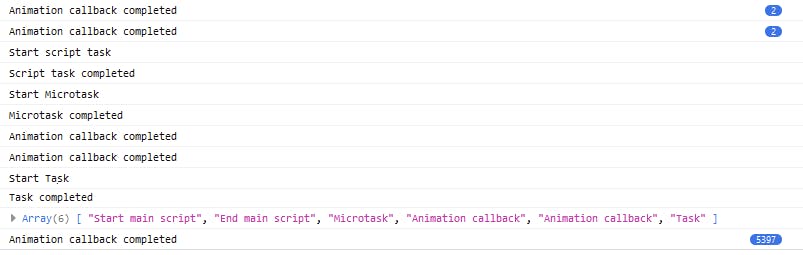
Edge results:
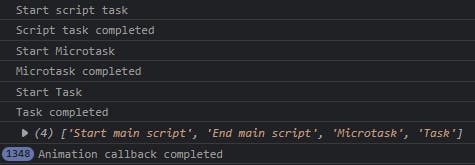
As I said, the order of execution differs depending on the browser and version. In the above example, Firefox and Edge seem to respect the standard order of execution, in the case of Firefox it seems it is possible to execute several Animation callbacks until it lets go of the next Task and in the case of Edge it seems that rendering operations do not so easily represent a priority over general tasks. Of course you can play with this example, increase the work time for example and see what happens. For sure you could obtain some different scenarios if changes are meaningful enough, but in general both browsers hold up to the standards. Also keep an eye out for timeouts minimum waiting time and throttling.
Ok, now notice how trying to identify the order of the EL operations after logging with the console API would have been skewed for Firefox. This indicating a run of the animation callback before the script that initiates rAF has been run in the first place. This can be caused by bugs or different implementations of the console web API.
It is also important to point out that rAF, an operation related to rendering, is also available in the worker's dedicated global purpose, even if it does not have direct access to the DOM elements in the window 🤔 Now, this may differ depending on the browser and their version, but it is generally possible because a web worker has access to the computation logic for rendering purposes and not to the rendered document and the actual rendering process. Other rendering functionality of web workers is the offscreen rendering API, OffscreenCanvas.
How is the event loop implemented in Node.js?

Aaahh yes, libuv, the Unicorn Velociraptor, or T-Rex, or uhh . . . whatever. This library is responsible for the implementation of EL in Node.js. The implementation for Windows systems can be found on GitHub as well as the implementation for UNIX systems.
In there you can see that these implementations are just a while loop conditioned by certain criteria. In terms of execution, it can be observed that it executes in order a list of different groupings of messages. A difference from the browser is that In this JS runtime, there is only one type of event loop, which means that if worker threads or child processes are spawned, they will all have an event loop that follows the same specifications.
At the time of writing this article Node.js 16.14.2 is the LTS version and Node.js 18.6.0 is the latest Stable version. From the LTS version onwards, in this commit you can see the last used version of libuv, i.e. libuv 1.43.0
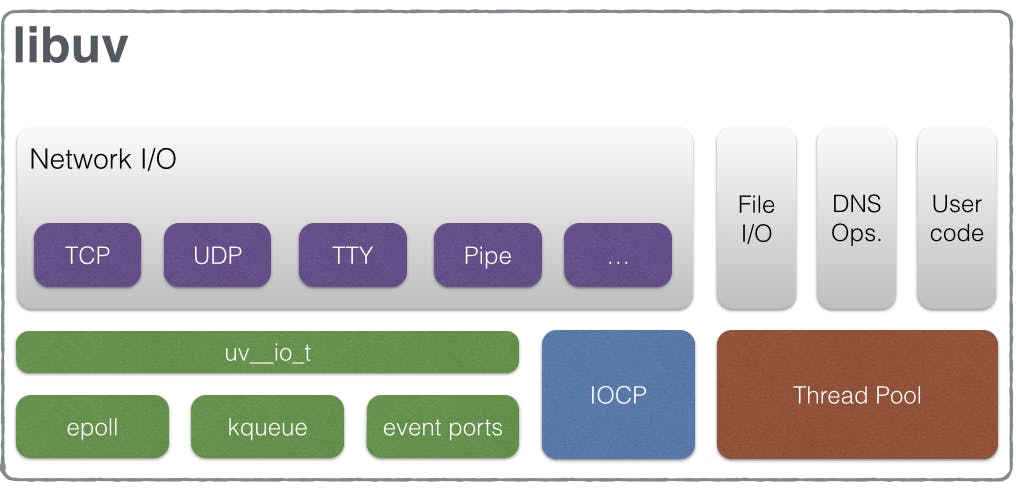
Below you can have a look on libuv's basic composition diagram.
Types of operations and their order
Alright now, hold on a minute, you reached about the middle of this article, congrats! Now, just a reminder, if you already spent some good time staring at the screen, probably while sitting on a chair or something, then now it would be a good time to take a minute to relax, get up, go for a walk, stare a little bit into the distance, don't forget to blink and drink your water! Alright? Good! 🙂
Getting back to our regular scheduled programming. Unlike the browser, in Node.js there are 4 types of main phases/operations in which you can set callback functions and 2 types of secondary phases, in which you can set callback functions.
Main phases:
- Expired Timers
- IO tasks
- Immediates
- Close Handlers
Secondary phases:
- nextTicks
- Microtasks (Promises/queueMicrotask)
The order is simple, first the main script is executed than it starts looping the main phases in the order they are listed above. At each main phase all of the associated callbacks are executed. Where do the secondary phases come into play, you may ask? Well immediately after the main script is executed and after each execution of one callback from a main phase, all the callbacks from each of the two secondary phases are executed in the order they are listed above.
Take notice that to enter the execution phase of IO tasks, EL does not wait until all immediate callbacks of the previous tick are all executed, especially if there are many of them enqueued.
In UNIX systems, but also in Windows systems, timer callbacks are stored in a min-heap, called timer_heap which is a property of the structure that represents the EL. While the pending IO, IO poll and immediate callbacks are memorized in queue data structures. And the way in which close handlers callbacks are stored denotes the fact that they are also stored in a queue-type data structure.
The code below shows the complete phases (including those that do not allow you to set callback functions) of the UNIX EL (the Windows ones are similar) from libuv 1.43.0. The comments were removed from code for better representation.
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
int timeout;
int r;
int ran_pending;
r = uv__loop_alive(loop);
if (!r)
uv__update_time(loop);
while (r != 0 && loop->stop_flag == 0) {
uv__update_time(loop);
uv__run_timers(loop);
ran_pending = uv__run_pending(loop);
uv__run_idle(loop);
uv__run_prepare(loop);
timeout = 0;
if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT)
timeout = uv_backend_timeout(loop);
uv__io_poll(loop, timeout);
uv__metrics_update_idle_time(loop);
uv__run_check(loop);
uv__run_closing_handles(loop);
if (mode == UV_RUN_ONCE) {
uv__update_time(loop);
uv__run_timers(loop);
}
r = uv__loop_alive(loop);
if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT)
break;
}
if (loop->stop_flag != 0)
loop->stop_flag = 0;
return r;
}
The 4 main phases are represented by the following functions:
Note that the execution order of a Close Handler callback depends on how the close event was issued. That is, it was closed abruptly (such as socket.destroy), then it will be treated regularly by being the last phase that is executed in the event loop, if it was closed in smooth mode (such as server.close), then the close callback will be treated as a nextTick callback.
Below is a mention from the official Node.js documentation about close callbacks:

Related to the differences in the node docs between timers and immediates the order of execution is not practically deterministic in all possible cases. It appears that determinism appears as soon as we have an IO callback. Since then it is clear that all immediate callbacks will execute first than followed by timer callbacks in the next tick of the loop.
The execution of callbacks from a queue of a main phase is done, in general, until exhaustion. However, there is also a limit up to which it executes callbacks. After each executed callback of a main phase, EL then runs all the callbacks from the secondary phases until it moves to the next callback from a main phase (this execution relationship between task and microtask has been discussed to be implemented in nodejs since 2018) .
Now, things may get a bit more complicated, so strap on to your sits. Even though so far it appeared that the secondary phases belong to the EL, well . . . they actually don't 😲 they are not even once mentioned in libuv, they can be considered add-ons maintaining and extending the general flow of the event loop.
Wait there is more!
There needs to be something that links the low level C code of libuv to the high level JS code. Between JS land (that is everything written in JS) and libuv (the C land practically) there is code that makes the binding between the two worlds and that code it resides in the C++ land 🤯 Yes folks you read it right, that is how JS can communicate with C and that is where from JS we can use the microtask and nextTick logic.
These Node.js bindings are actually quite a broad topic that deserves its own separate discussion. But to keep it short, the C++ ==> JS most significant binding point to highlight how the secondary phases are added on to libuv's EL is represented by the InternalMakeCallback function.
Basically, this C++ function is where the propagation to the JS land of the execution command for a main phase callback coming from the EL is triggered. And besides that here is also where it's triggered the propagation to the JS land of the execution command for all secondary phases callbacks, but this time coming not from EL, but either from C++ land in case of nextTicks or from the V8 engine for promises.
Finally the code that traverses the these two queues is located in JS Land, in the processTicksAndRejections function.
Libuv is not aware of the presence of any microtask or nextTick queues. Only C++ Land and JS Land are aware of their existence.
Ok, I know for some of you this might be a little bit hard to keep track of

And for good reasons. It actually could be elaborated even further, but I think summarizing it to those things that are most important is enough for the scope of this lecture, after all the binding points, API mappings, their mechanisms of action and whatnot are actually quite numerous.
Also keep in mind that the current 16.14.2 LTS version gradually received changes for its bindings, so in this regard older versions may differ quite a bit.
Fortunately for those who are interested to know more, starting from the references presented in here and going towards JS or C, you can actually follow up (or track down 🙃) these bindings by yourself.
Anyways, it will get easier towards the end, I promise 😉🤞
Examples of event loop operations in Node.js
Add the script below in a file, name it whatever, myScript.js if you will, and run it with Node.js. For example >node myScript.js
import fs from "fs";
import net from "net"
function workTime(mls) {
const startDate = performance.now();
let currentDate = null;
do {
currentDate = performance.now();
} while (currentDate - startDate < mls);
}
function runTask(taskName, timeForRunning) {
queueNextTickArray(nextTickArray);
queueMicrotaskArray(microtaskArray);
if (timeForRunning) {
workTime(timeForRunning);
}
eventLoopPhasesArray[index++] = taskName;
}
function runTimmer() {
runTask("Timmer", 500);
}
function runImmediate() {
runTask("Immediate", 500);
}
function runNextTick() {
eventLoopPhasesArray[index++] = "Next tick";
}
function runMicrotask() {
eventLoopPhasesArray[index++] = "Microtask";
}
function runCloseHandler() {
runTask("Close Handler", 500);
}
function queueTaskArray(taskArray, queueFucntion) {
taskArray.forEach((taskCallback) => {
queueFucntion(taskCallback);
});
}
function queueMicrotaskArray(microtaskArray) {
queueTaskArray(microtaskArray, queueMicrotask);
}
function queueNextTickArray(nextTickArray) {
queueTaskArray(nextTickArray, process.nextTick);
}
function queueTimmerArray(timmerArray) {
queueTaskArray(timmerArray, setTimeout);
}
function queueImmediateArray(immediateArray) {
queueTaskArray(immediateArray, setImmediate);
}
function queueCloseHandlerArray(closeHandlerArray) {
queueTaskArray(closeHandlerArray, (closeHandlerCallback) => {
const socket = net.createConnection({port: 8080});
socket.on("close", closeHandlerCallback);
socket.destroy();
});
}
function ioCallback(err) {
eventLoopPhasesArray[index++] = "IO";
if (err) {
return console.log(err);
}
if (loops-- == 0) {
console.log(eventLoopPhasesArray);
return;
}
queueTimmerArray(timmerArray);
queueImmediateArray(immediateArray);
queueNextTickArray(nextTickArray);
queueMicrotaskArray(microtaskArray);
queueCloseHandlerArray(clsoeHandlerArray);
fs.readFile('someFileOnYourComputer.txt', 'utf8', ioCallback);
}
const eventLoopPhasesArray = [];
let index = 0;
let loops = 2;
const timmerArray = Array(2).fill(runTimmer);
const immediateArray = Array(2).fill(runImmediate);
const nextTickArray = Array(2).fill(runNextTick);
const microtaskArray = Array(2).fill(runMicrotask);
const clsoeHandlerArray = Array(2).fill(runCloseHandler);
fs.readFile('someFileOnYourComputer.txt', 'utf8', ioCallback);
So this example is pretty simple, here are a few observations:
- As with the example for browsers, we register the order of operations by adding their name to an array.
- You can pass arrays of callbacks to be synchronously scheduled for each phase of EL, except IO, using queue. . .Array() functions.
- The loop starts with an IO callback, that is to avoid the uncertainty of order from the beginning of the program of timers and immediates.
The result should be similar to the one below:
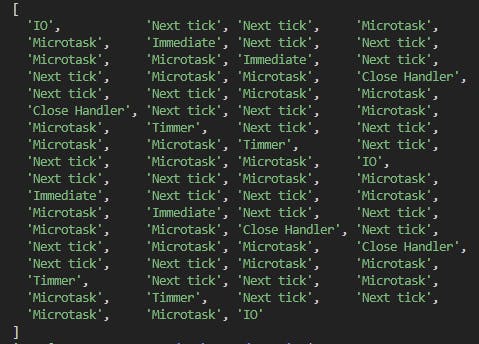
You can play with this example and test different scenarios. For example you can enqueue a nextTick at the same level with the first fs.readFile and see what happens.
What are the general principles of multithreading? Something JS specific?

As I specified above, JS runtimes complement the concurrent experience of EL with a thread implementation technique. This resulted from the computational necessity of some more demanding tasks in which parallelism through threads proved to be useful.
There are also cases in which parallelism needs to be reached by other means, like for example to improve tolerance to failure. Here it comes IPC. To further expand on this subject you can check Chromium's approach and also Firefox's approach.
In browsers JS threads are generally known as web workers, and in Node.js they are called worker threads.
A few bits of theory here. The concurrent nature of a system can be achieved using two models, preemptive multitasking and cooperative multitasking. The later we talked about already, the former it means quite the opposite of the later, that is pieces of code hand on the baton to each other only under the decision of a common supervisor, like the operating system for example.
With great power comes great responsibility! And that is why programs in Node.js and browsers, whether with or without threads, are exposed to race conditions. You can check an article by Luciano Mammino about race conditions in JS for further details on this topic.
Until I get further into the specific details of JS threads, it is also worth mentioning a few laws about the maximum speed that can be reached in paralyzing the execution of a program. In this context, according to the theory, there are several laws, some more practical than others depending on the situation, but all specify how much the execution time of a program can be minimized by reaching an upper limit of performance through parallelization that it cannot exceed no matter how many more processors are added into the mix. Often the usage of these laws, more for orientation purpose, happens in the architecture point of an application.
Ok, here they are:
Details about these two are outside the scope of this discussion, but if you want to purse the theory about them you can follow the leads above.
And one more thing, the multithreading technique, in general, is also supported by the stagnation of the processing speed of only one CPU core. This is something that was observed in Moore's law.
How does JavaScript work with threads in browser?
In browser, threads are known as web workers and are made available through an internal API.
These web workers have general specifications mentioned in the HTML standard according to which implementations in different browsers are oriented, but depending of browser and version these might slightly differ. Hmm I wonder where have I heard that before 🤔
In terms of relationship between threads, usually those threads that spawn other threads are called parent threads, and the other ones child threads. Those who are children of same parent are called sibling threads. Pretty straight forward, huh?
Communication between child threads and the parent thread is done with the help of the postMessage function or message event function, which are the access points in an internal MessageChannel created for communication between parent and child thread.
You can also create your own MessageChannel instances for communication between threads of any kind and browsing contexts.
There are 3 types of workers in browser:
In terms of composition, according to specifications, when a web worker is created it should receive its own instance of EL and memory resources separated from the other threads.
On efficiency side of things, most browsers implement something called thread pool, basically a group of already created threads that can be used for CPU intensive operations. The number of threads in the pool does not have to be very high, as discussed earlier the best effort done in parallel is limited by the hardware. You can check out the thread pool implementation for Chromium browsers.
Some examples of Web Workers can be found from MDN.
How does JavaScript work with threads in Node.js?
Alright, I guess this is the last lesson. Not much more left to go and you'll witness the true powers of concurrent programming. So, what are you waiting for? Let's do it.

In Node.js threads can be used with the worker_threads.js module. This have become a stable functionality starting with Node.js 12.15
Regarding composition, each worker thread has its own instance of V8 engine with queues for microtasks and their own memory heap, plus their own instance of libuv event loop.
Just like browsers, in order to make working with threads more efficient Node.js also supports the thread pool concept.
In Node.js communication between threads can be done in an asynchronous 2-way-communication style by using MessageChannel objects.
A few more words about data passing. There are 3 ways to pass data between threads:
- Cloning data
- Transfer (could be done with ArrayBuffer, MessagePort)
- Shared data (with SharedArrayBuffer)
A quick tip here, the Atomics Module can be used to synchronize shared data. It is already integrated since Node.js version 16 LTS onwards ⬆️ and in modern browsers as well.
In terms of bindings, the creation and initiation of threads starts from the JS land with the worker.js file. The Worker class from JS Land is linked in the C++ land to the file node_worker.cc, by calling a constructor called WorkerImpl, which is a bounding point to C++ land.
Going back to worker composition, in node_worker.cc you can actually see how new resources are allocated for the thread, such as the parent MessagePort, its own libuv EL, its own Heap, an isolated V8 engine, etc.
Access from user land (that is whatever JS files written by the users) is provided by worker_threads module exports, we know that. But regarding communication concepts besides MessgaePort and other similar constructs, MessageChannel is also available by being imported in worker/io.js file. This is actually a bounding point to C++ land by being associated to the MessageChannel function from the node_messaging.cc file.
Now, thread initiation, that includes resource allocation, is started at the moment of creation with new Worker(. . .). This Worker constructor implementation resides in worker.js file, and when this[kHandle].startThread() it's called inside it it will activate a binding point to C++ land by calling to its association the StartThread function from node_worker.cc which ends up doing all the dirty work for us 😎
Finally, the actual execution of the script by the newly created thread starts in the worker_threrad.js file. More precisely when the script it's loaded in there.

Examples of operations with worker threads
Below is the script file to be ran:
import {Worker, MessageChannel} from 'worker_threads';
const worker1 = new Worker("./workerScript.js");
const worker2 = new Worker("./workerScript.js");
let {port1, port2} = new MessageChannel();
worker1.on("message", (message) => {
console.log(`MAIN THREAD: Message from child worker [id: ${worker1.threadId}] is "${message}"`);
});
worker2.on("message", (message) => {
console.log(`MAIN THREAD: Message from child worker [id: ${worker2.threadId}] is "${message}"`);
});
worker1.postMessage({port: port1, id: worker1.threadId, siblingId: worker2.threadId}, [port1]);
worker2.postMessage({port: port2, id: worker2.threadId, siblingId: worker1.threadId}, [port2]);
And below is the workerScript.js file:
import {parentPort} from "worker_threads"
parentPort.on("message", (message) => {
const {port, id, siblingId} = message;
parentPort.postMessage("Got the channel details");
port.on("message", (message) => {
console.log(`WORKER THREAD[ID: ${id}]: Message from sibling worker [id: ${siblingId}] is "${message}"`);
});
port.postMessage("Hakuna Matata!");
});
A few words about what this code is supposed to do:
- The parent thread creates two child threads that are supposed to talk between each other.
- To do so it also creates a MessageChannel whose ports it transfers, one each, to the child threads.
- Then the siblings can talk with each other.
The result should be similar to the one below, the order does not have to be the same.

Feel free to play around with this example. Maybe try using one file for all threads, see how you can do that.
Hint: you may need to use the isMainThread property.
Conclusion
And that pretty much sums it up folks. Of course, there are more things to talk about on this topic, but that can be for another time.
Most importantly, you now not only have a good understanding of the big picture of concurrency in JS runtimes and how it all comes together, but you also have good leads and know where to look 🔎
And last, but certainly not least, thank you for your interest in software engineering!
References
- nodejs.org/docs/latest-v16.x/api/index.html
- github.com/nodejs/node/tree/v16.14.2
- docs.libuv.org/en/v1.x
- github.com/libuv/libuv/tree/v1.43.0
- nikhilm.github.io/uvbook/index.html
- libevent.org
- searchfox.org/mozilla-central/source
- github.com/chromium/chromium
- github.com/libevent/libevent
- nodejsdesignpatterns.com
- firefox-source-docs.mozilla.org
- chromium.org/developers
- v8.dev/docs
- spidermonkey.dev/docs